Lorenzo Taddei, CRM Analyst | Sustainability Bologna, Italy
About myself
I am a Data analyst with experience in CRM and marketing.
I have strong expertise in SQL, Tableau, predictive modeling and reporting automation.
After almost a decade in analytics, I have started exploring the field of sustainability. I recently started the course Junior Expert in Sustainability 5.0 and began developing an entrepreneurial idea focused on waste repurposing.
My career
Work History
TUI , Portugal and Netherlands (2.5 yr) CRM & CX Analytics - Dashboard automation, campaign performance analysis.
This project has the goal to build a tool that may be employed by Airbnb hosts to understand the market price of their accommmodation.
The study employs Airbnb data that refer to Amsterdam listings, where, after cleaning the publicly available dataset, an analysis that observe which variable are contributing the most in determining the price is carried out.
This feature relevance analysis is performed by observing the individual features contribution of a random forest. The random forest takes as input the most relevant features in the dataset and attempt to estimate the listings' prices from them.
The plot on the side shows the most relevant features' contribution to the model. Since the App is designed for hosts that do not have an accomodation yet, the features selected are the one in red.
By means of the Shyny app server, an app is deployed (find the link below). The app 'Airbnb perfect price' takes as input the features of the accommodation and insert these input as values that feed the Random Forest.
The model computes the price that a host should be charging on Airbnb in order to be perfectly aligned with the competition.
Explore the app that allows Airbnb hosts to better understand the market and charge fair prices here:
Web page that presents the web app, its uses and limitations.
Web app version 2 : to charge perfect prices for users that already have a listing
This app is created with Shiny app: an R package that allows to build interactive web apps straight from R. Shiny App course certificate .
Click for more
Customer Lifetime Value in mobile gaming
(SQL, RStudio)
MSc Thesis×
Latent attrition models in mobile gaming. The role of RFM values and playing behaviours covariates in Customer Lifetime Value Predictions
This study, in collaboration with an international gaming company, explores new methodologies to predict customer future spending on mobile games. The game observed is a mobile freemium game, for privacy reasons neither the name of the game nor the data employed are not published. The predictor utilized in the study is the Pareto NBD, a latent attrition model, which estimates simultaneously two different processes of customers:
- Attrition (responsible for churn) - Transactional (models the number of purchases)
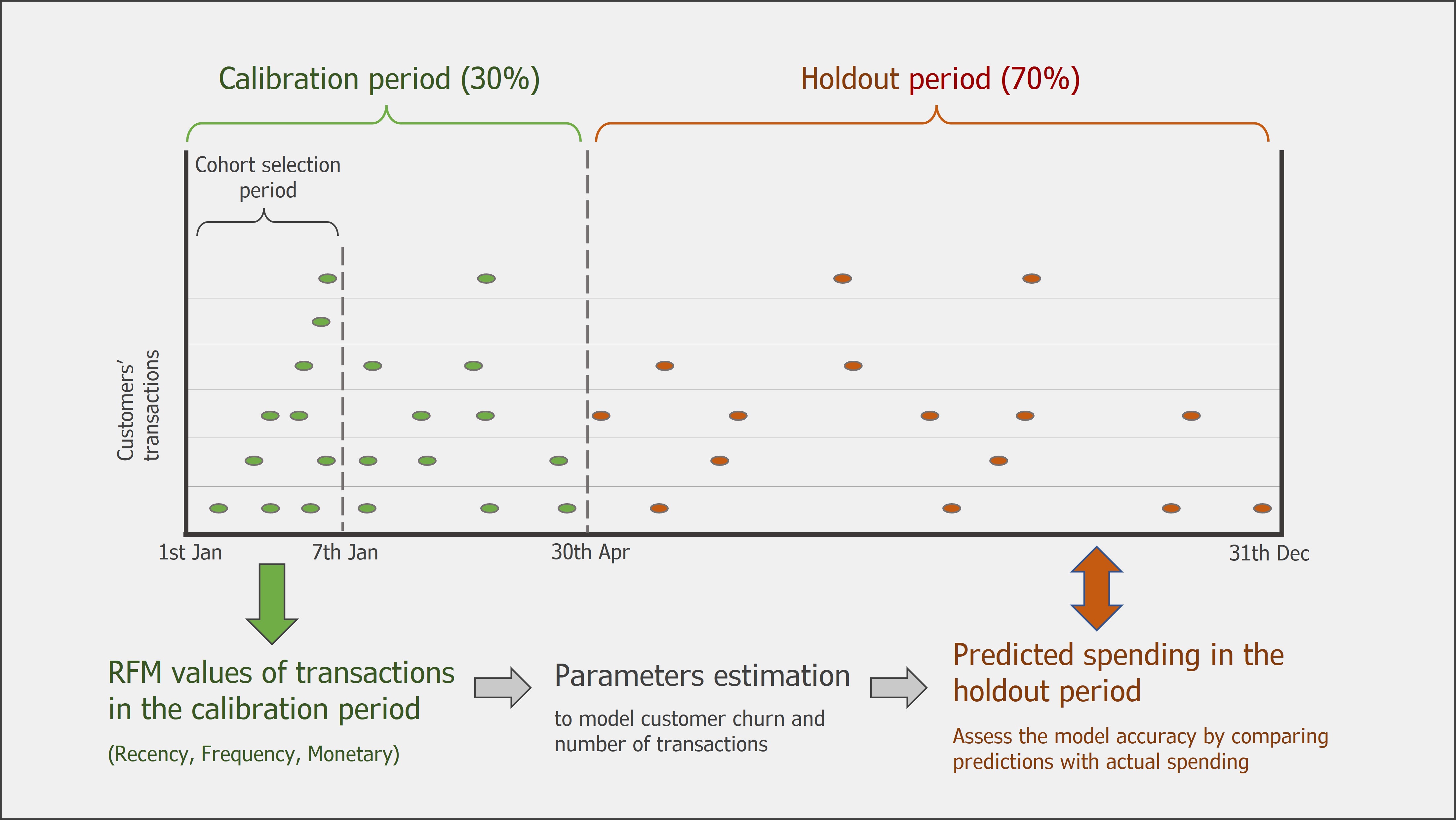
The Standard version of the Pareto NBD employs only the RFM values for the whole customer base. These values are Recency (when the last purchase took place), Frequency (how many purchases the customer has done in the observed period), and Monetary (average amount of past transactions) values. The model performs a holdout split, and only employs the RFM values only in the Calibration period, and computes future spending predictions in the validation period. The image below summarizes this process.
The analysis takes into consideration a cohort of customers that made their first purchase on a certain week of the year, and their transactions are observed for the whole following year. The calibration period consists of the first four months of the year and the remaining ones correspond to the validation period. As the figure shows the predicted spendings in the holdout (or validation period) are then compared with the actual data, available in the dataset. This allows to asses the accuracy of the model and eventually claim whether including the covariates improve the predictions.
Pareto NBD standard
The results of the Pareto NBD standard show an how much purchases and churn are frequent in the onìbserved population. The dropout rate =0.076 , tells us that the average lifertime of a customer is 13.5 days, and that after 15 days from the beginning of the observation period we are left with 50% of the origilal customers.The purchase rate =0.089 , is the average probabiliy that an active customer (still alive according to the attrition process) makes a purchase in a day. Both rates are quite low, illustrating how the mobile freemium industry is characterized by very high abandon rate and non- frequent puchases.
The predictions of the model can employed in diffrent ways. In the study it is observed how accurate predictions are at the aggregate and the individual level. The observed dataset consist of 581 customers and the MAE (mean absolute error) of the Pareto NBD is =4.27, while the total residuals is =0.52. This highlight the good in-saple fit of the model and that it can successfully be employed to evaluate the profitability of a certain customer base as the image below shows.
A good predictive power is also observed in individual level spending predictions. This application is especially important when performing tageted marketing campaigns, where only the most profitable customers want to be reached. The plot below compare the predicted number of purchases in the holdout period given the number of transactions done in the calibration period.
Finally, the model is employed for a classification task, to detect top spending customers. Here, the obseved units are divided in non top-spending and top-spending. The results yielded by the model depend on the % of costumers that wants to be reached, the best results are observed when we try to identify the top 5% of spending clients. The hit rate (or precision) is =0.56. This means that the model can spot 56% of these most valuable clients.
In terms of out-of-sample performance, the computed Pareto NBD Standard yield surprising results. The MAE is even lower when predictions are made on an external sample.
Pareto NBD with covariates
The improvement of the model when accounting for the covariates are not significant. This negative results is very likely observed because an important assumption of the covariates is not respected in thos case stusy. The assumption is that the covariates remain constant between the calibration and validation period. Since the control variables that are considered include playing behaviors, such as time spent on the game or number of session during a week, these are very likely to change across the observed period.
As the plaot shows when including the covariates in the model the performance of the model worsen. The predicted number of purchases is overestimated, and the MAE is higher then the one of the Pareto NBD Standard.
Web scraping e-books from Bol.com
(Python: Selenium, Pandas)
Inspecting the e-books market via web scraping on Bol.com×
The e-book market has significantly grown in recent years, with more and more readers opting for digital versions of their favorite books. The advantages of e-books include their accessibility, portability, and low costs. From the authors’ point of view, e-books provide opportunities to reach a wider audience and create generate higher profits due to the lack of printing costs. Given the potential of the e-book market, it is essential to stay up-to-date on market trends and customer preferences.
The goal of this project is to provide authors and publishers with up-to-date information regarding e-books. More specifically, I built a web scraper that gathers important information on all e-books for kids available on the website Bol.com. The goal of this project was to extract data such as price, topics, number of pages, languages, and other relevant details, which could then be used by writers to create e-books in the ideal format.
To accomplish this, I used a web scraping tool to navigate the website and extract the desired information from the e-book listings of Bol.com. The screenshot below shows the information available on the main navigation page of kids’ e-books. Various insights can already be extracted from this page such as:
- Price - reviews - Language - Number of pages - Other available formats of the book (and respective price) However, other relevant information had to be extracted from the specific e-book page. This information are shown in the 2nd screenshot (taken from the book page): - Categories - Reading capabilities (devices) - Recommended age of kids
To obtain the required data the scraper carried out the following tasks:
- Navigate through all the pages of the category (500 pages) - Collect the links (seed) of all the e-books in each page - Navigate in every link of the seed and extract all the information of interest
The information gathered from this project was used by a writer to create an e-book with illustrations for kids, aligned with market trends and customer preferences. The collected dataset may also help to identify areas of opportunity for creating e-books that filled gaps in the market.
The following repository contains the source files used for extracting the data and the final dataset generated: Web scraping from Bol.com
Multiple Correspondence Analysis on chess games
(Excel, RStudio)
BSc Thesis×
Multiple Correspondence Analysis on chess games
This project aimed to understand the underlying patterns and correlations among various features of real-life chess games. The study collected data from a large number of publicly available past chess games (on chessgames.com), including the opening sequence, information on the moves made, pieces captured, the players involved, and the outcome of the game.
The main focus of the thesis is an MCA (multiple correspondence analysis), a statistical technique that allows for the identification of latent variables from a set of observed features. In this study, the collected data on chess games was used to define new latent variables that cannot be in other ways observed. The results of the analysis revealed two main latent variables: "level of dynamism" and "level of complexity". The level of dynamism refers to the degree of movement and activity in the game, while the level of complexity refers to the number of strategic options available to the players.
These two variables are useful to describe which categories of the variable affect the dynamism and complexity of the games. Since the outcome of the analysis refers to the classes of the variables, overall conclusions can be drawn. For instance, games played in t recent years have a higher level of complexity, while the less time it is given to players to play, the more dynamic the game will be, and so on. However, given the descriptive nature of MCA it may be ye possible to define .thesis also presents a model that can be used to measure any chess game by these two variables, making it possible to quantify and compare the dynamics and complexity of different games. This model can be applied to analyze any chess game and understand its underlying characteristics, making it useful for coaches, players and researchers.
Overall, this thesis makes a significant contribution to the field of chess research by providing new insights into the dynamics and complexity of chess games through the use of statistical methods. The findings of this study have the potential to improve the understanding and analysis of chess games and can be applied to improve the performance of coaches and players.
The Impact of a Failed Acquisition: study case of Kraft Heinz and Unilever
(Excel, SPSS)
Case study ×
A Comprehensive Study of the Effects of a Failed Acquisition: The Kraft Heinz and Unilever Case.
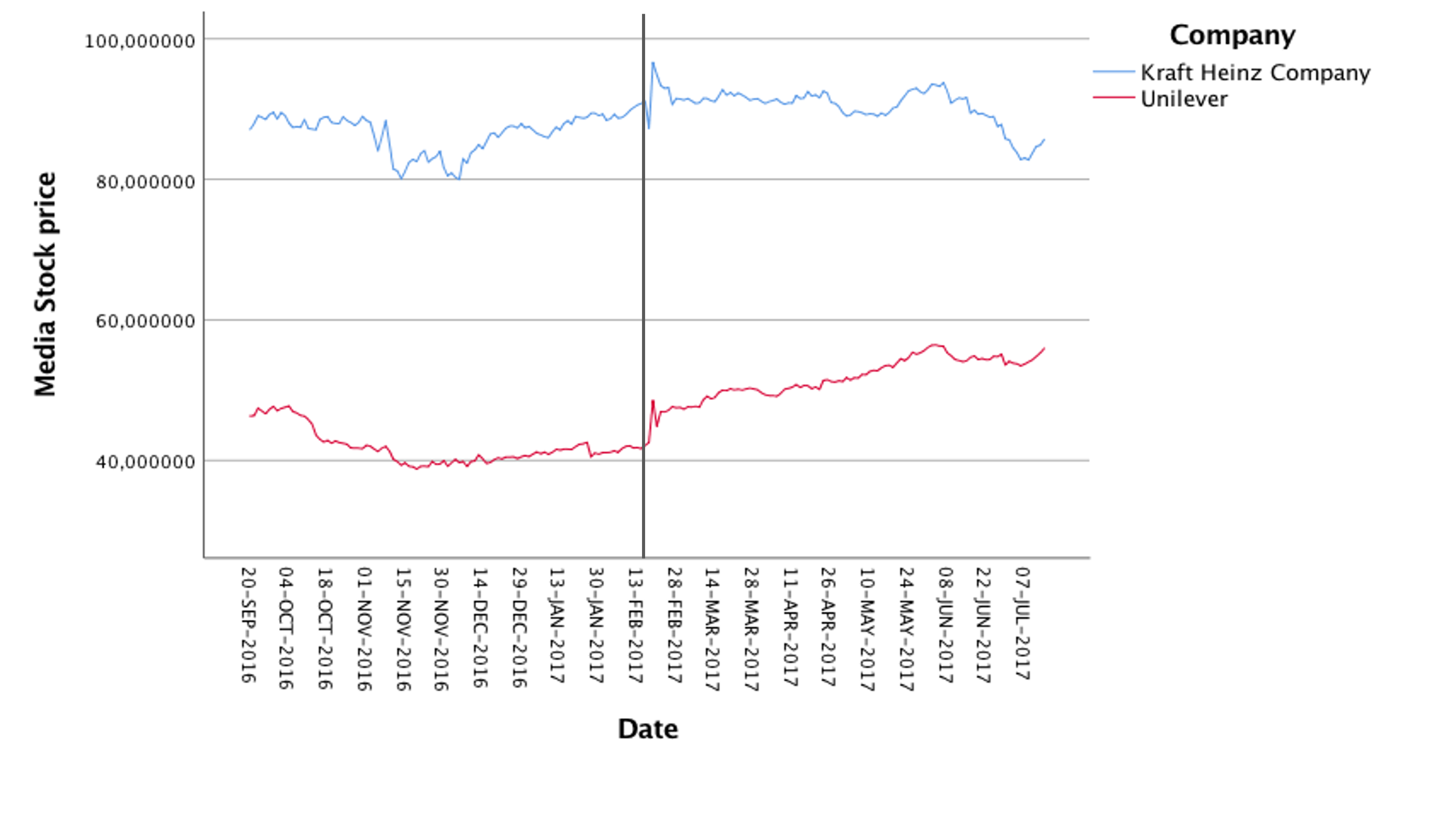
The focus of the project is to analyze the effect of a failed acquisition in the stock market. In 2017, Kraft Heinz attempted to acquire Unilever, but after rumors of the takeover, Unilever rejected the offer. In this study, the historical stock prices of both companies were observed from 2016 until after the rejection of the offer to estimate the economic consequences of the event.
To estimate the entity of the event, the study started from Yahoo finance data to extract all the necessary information regarding the two companies around the event date. The analysis was performed using SPSS software to gain insights into the stock returns generated by the event. The results of the study showed that the event had a more positive impact on Unilever's abnormal stock returns (discrepancy between observed returns and the expected rate), which was supported by investors in their decision to reject the offer from Kraft Heinz. The chart below show the returns of stock before and after the event for both companie. This folder contains further insight to better picture the situation of the two companies before and after the event.
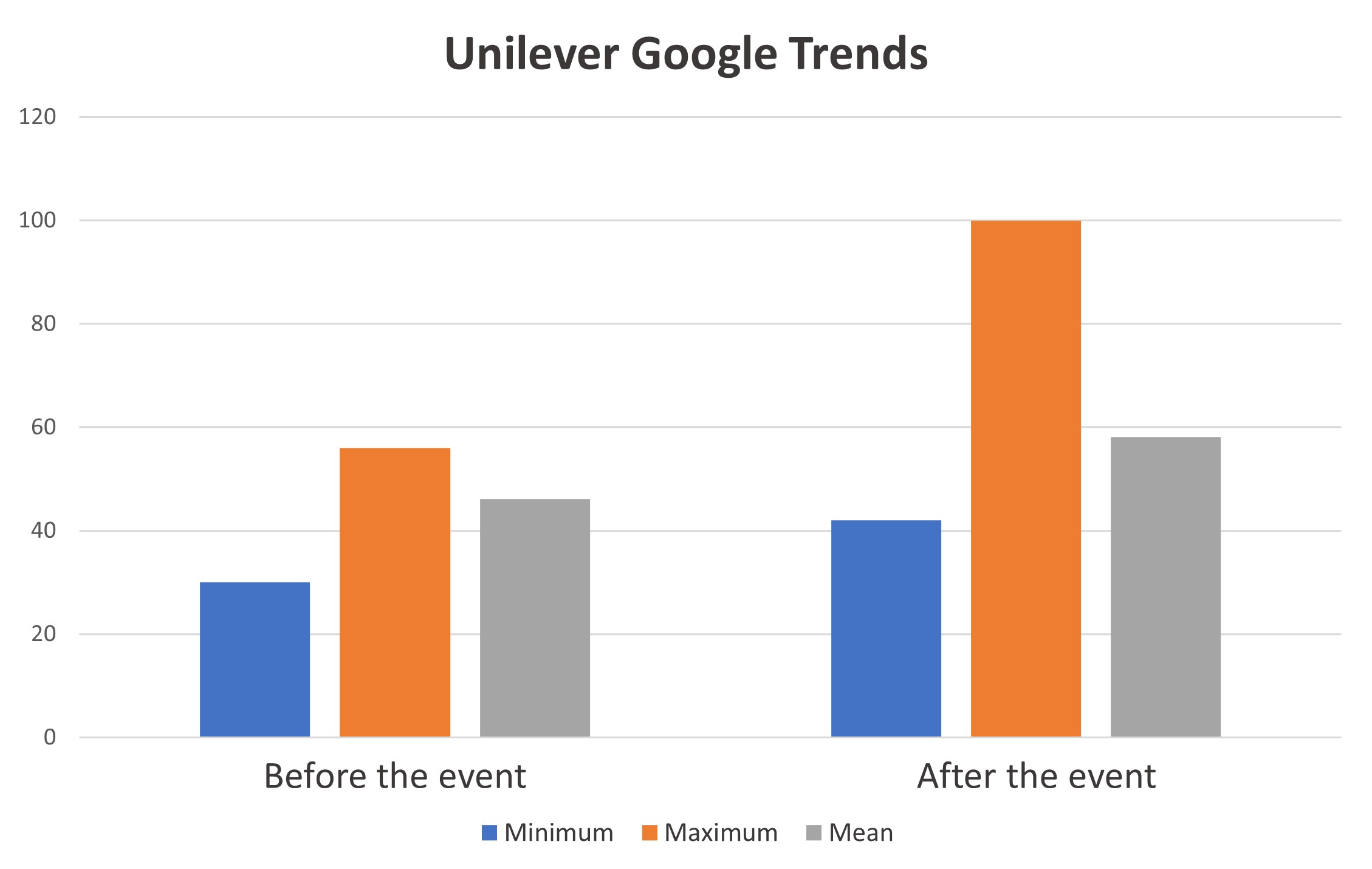
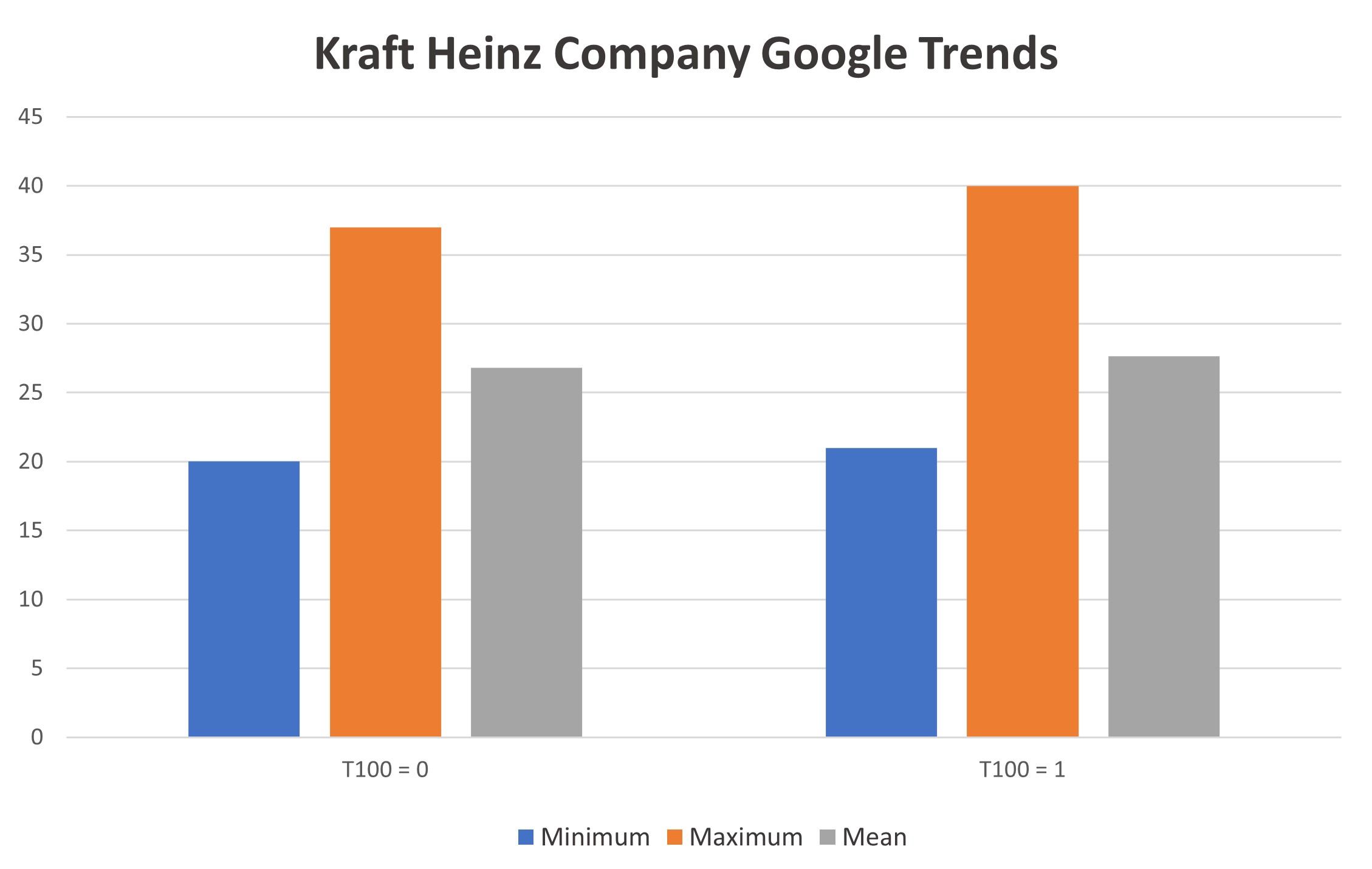
In addition, the use of Google Trends data provided a comprehensive view of the event and its impact on the public's interest. This information complemented the stock market analysis, providing a more complete understanding of the consequences of the failed acquisition.
In conclusion, the study provides valuable insights into the impact of a failed acquisition on stock returns. The results were statistically relevant and innovative, as not much research has been done on this topic in the past. The study highlights the importance of considering the consequences of such events and the impact they have on the stock market, as well as the public's interest and perception of the companies involved.
Important note
The projects displayed here represent a selection of my work and are intended to highlight some of my skills and areas of expertise. I can provide further details upon request.
Please note that work carried out within companies is not shown for confidentiality reasons.
proficient
native
intermediate
basic
conversational
Side interests
Blackboards for businesses
During Covid times I started doing Blackboard menus for a Street food Restaurant.
I've kept the habit of offering this service to local bars and restaurants while in the Netherlands and in Portugal.
Find below my websites explaining the service I offer and showcasing some of my works:


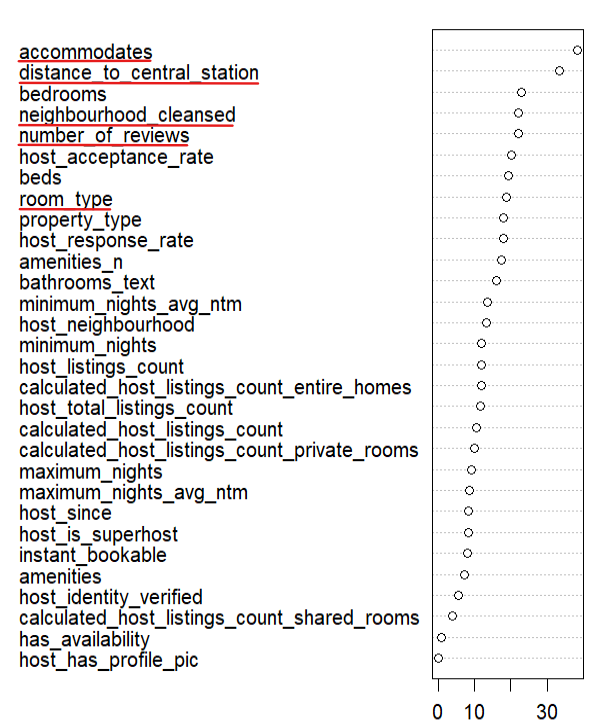 The plot on the side shows the most relevant features' contribution to the model. Since the App is designed for hosts that do not have an accomodation yet, the features selected are the one in red.
The plot on the side shows the most relevant features' contribution to the model. Since the App is designed for hosts that do not have an accomodation yet, the features selected are the one in red.
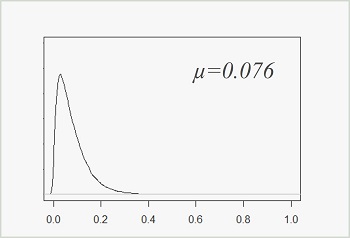 The results of the Pareto NBD standard show an how much purchases and churn are frequent in the onìbserved population. The dropout rate =0.076 , tells us that the average lifertime of a customer is 13.5 days, and that after 15 days from the beginning of the observation period we are left with 50% of the origilal customers.
The results of the Pareto NBD standard show an how much purchases and churn are frequent in the onìbserved population. The dropout rate =0.076 , tells us that the average lifertime of a customer is 13.5 days, and that after 15 days from the beginning of the observation period we are left with 50% of the origilal customers.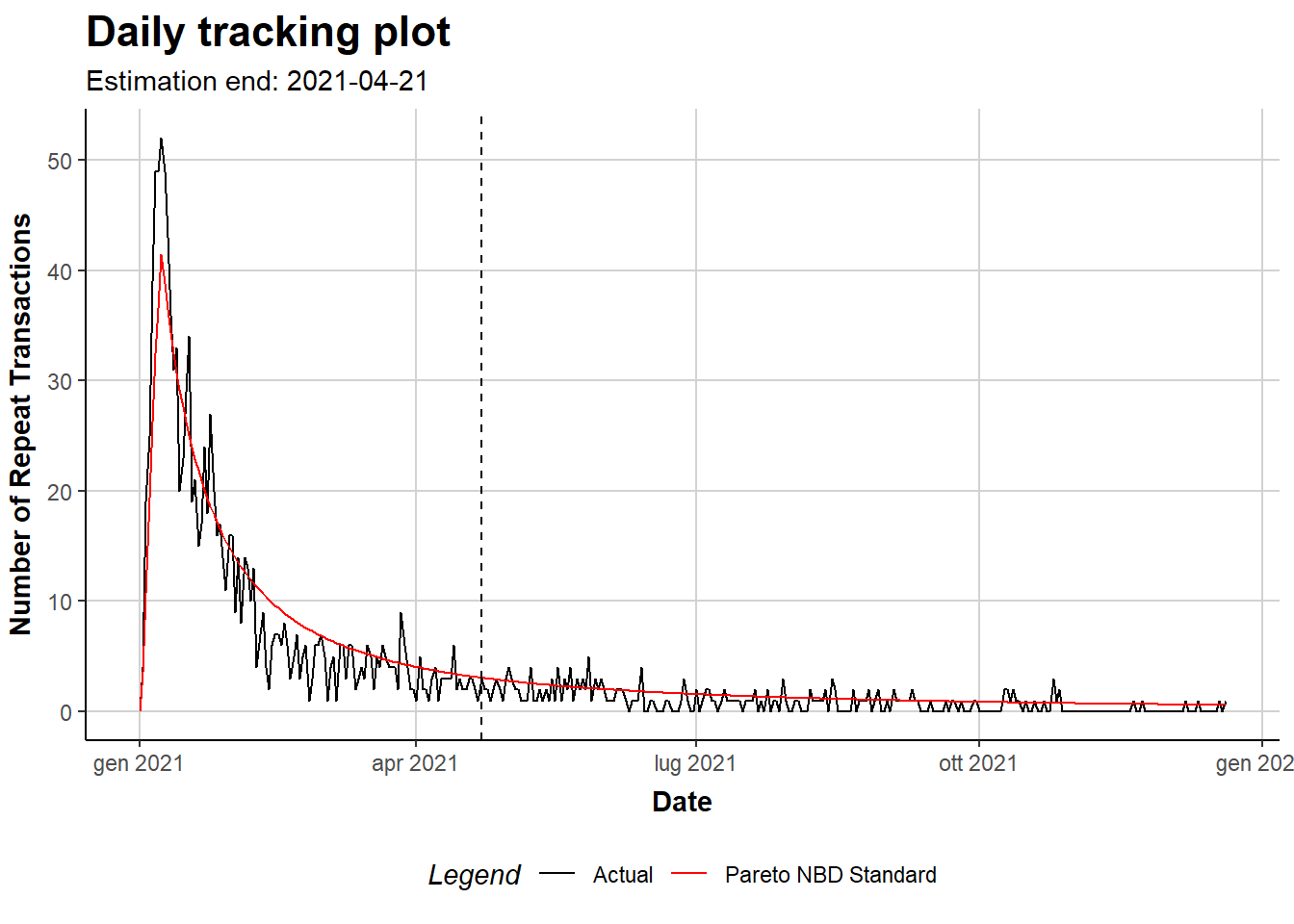
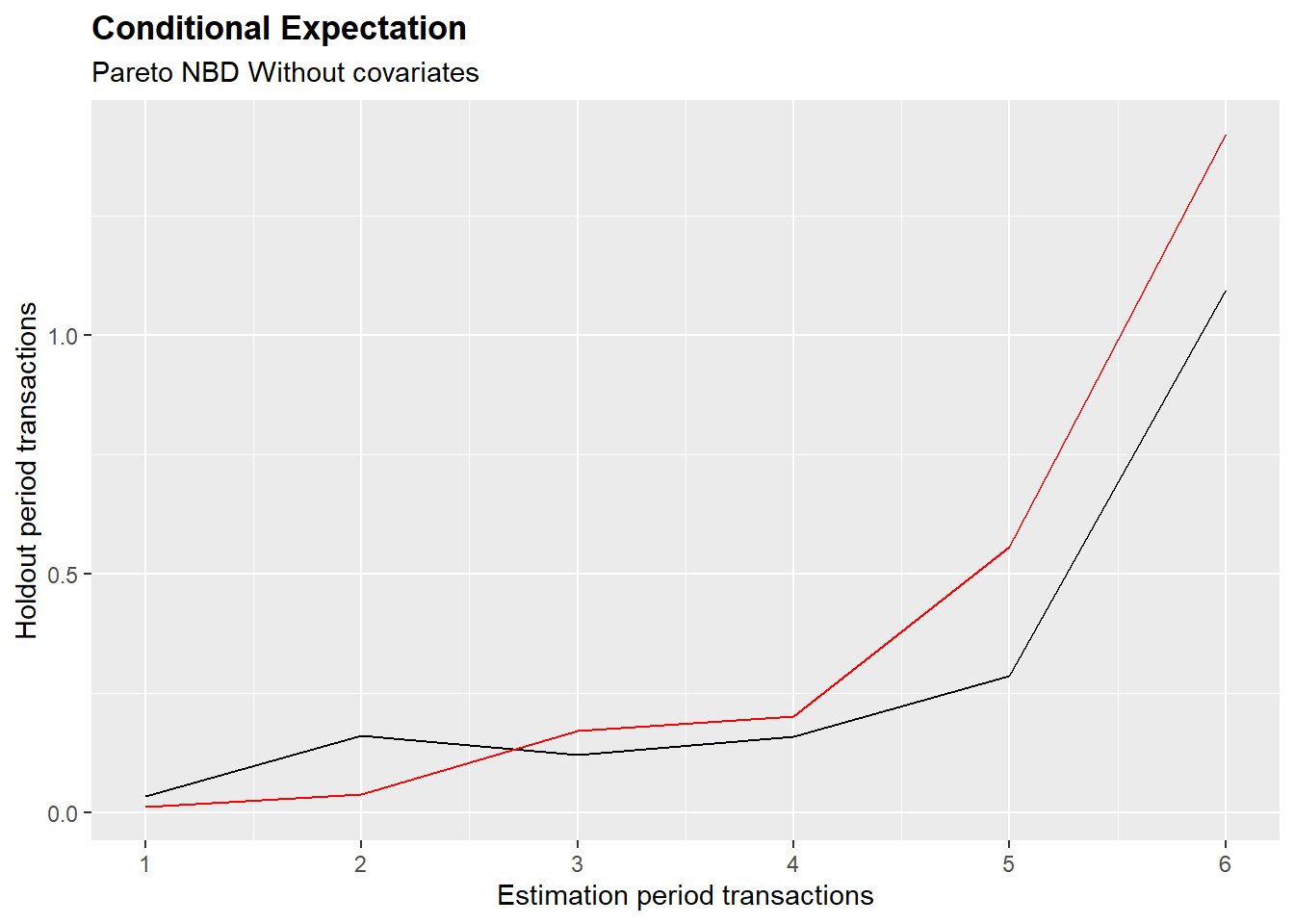 A good predictive power is also observed in individual level spending predictions. This application is especially important when performing tageted marketing campaigns, where only the most profitable customers want to be reached. The plot below compare the predicted number of purchases in the holdout period given the number of transactions done in the calibration period.
A good predictive power is also observed in individual level spending predictions. This application is especially important when performing tageted marketing campaigns, where only the most profitable customers want to be reached. The plot below compare the predicted number of purchases in the holdout period given the number of transactions done in the calibration period.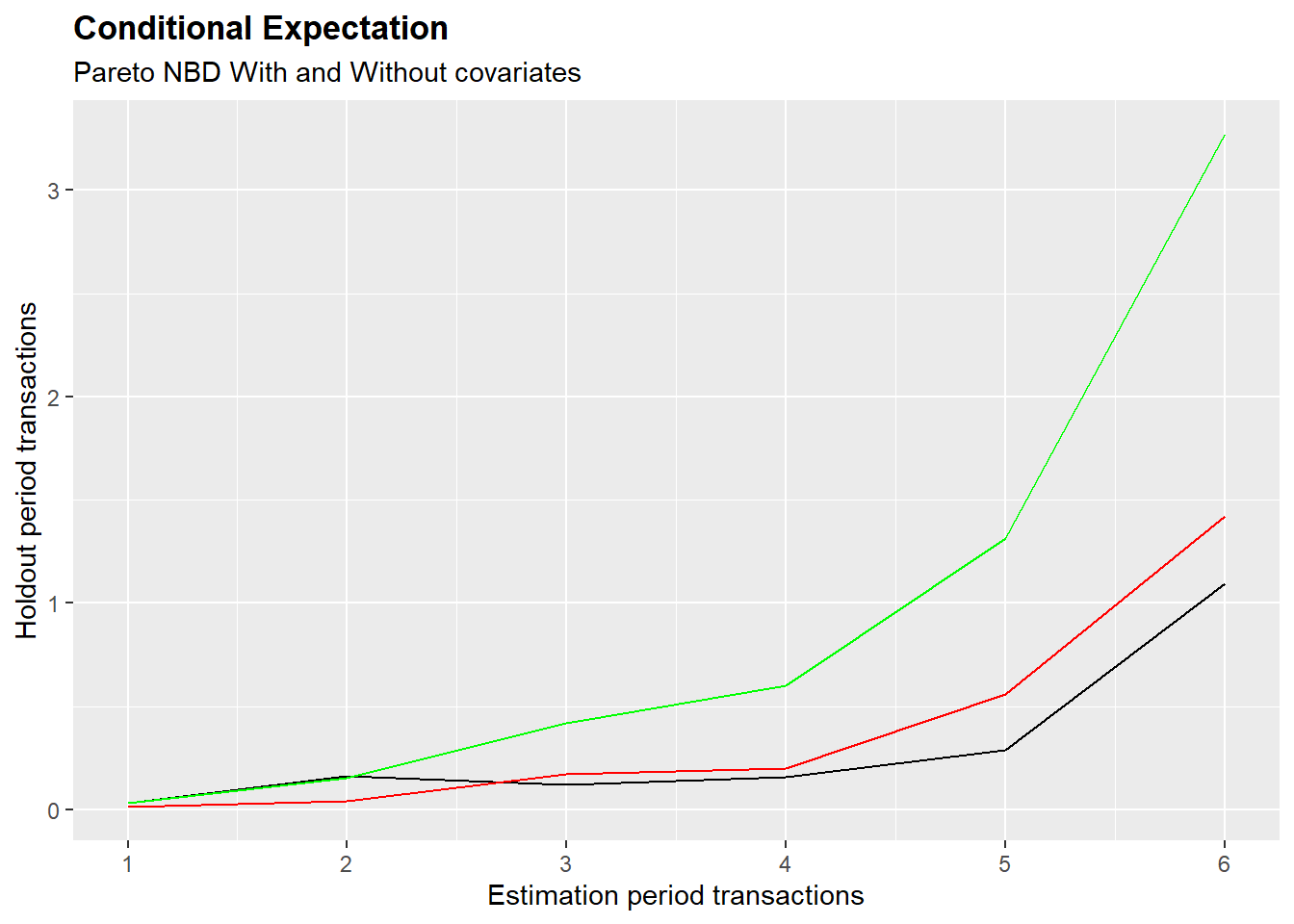 As the plaot shows when including the covariates in the model the performance of the model worsen. The predicted number of purchases is overestimated, and the MAE is higher then the one of the Pareto NBD Standard.
As the plaot shows when including the covariates in the model the performance of the model worsen. The predicted number of purchases is overestimated, and the MAE is higher then the one of the Pareto NBD Standard.

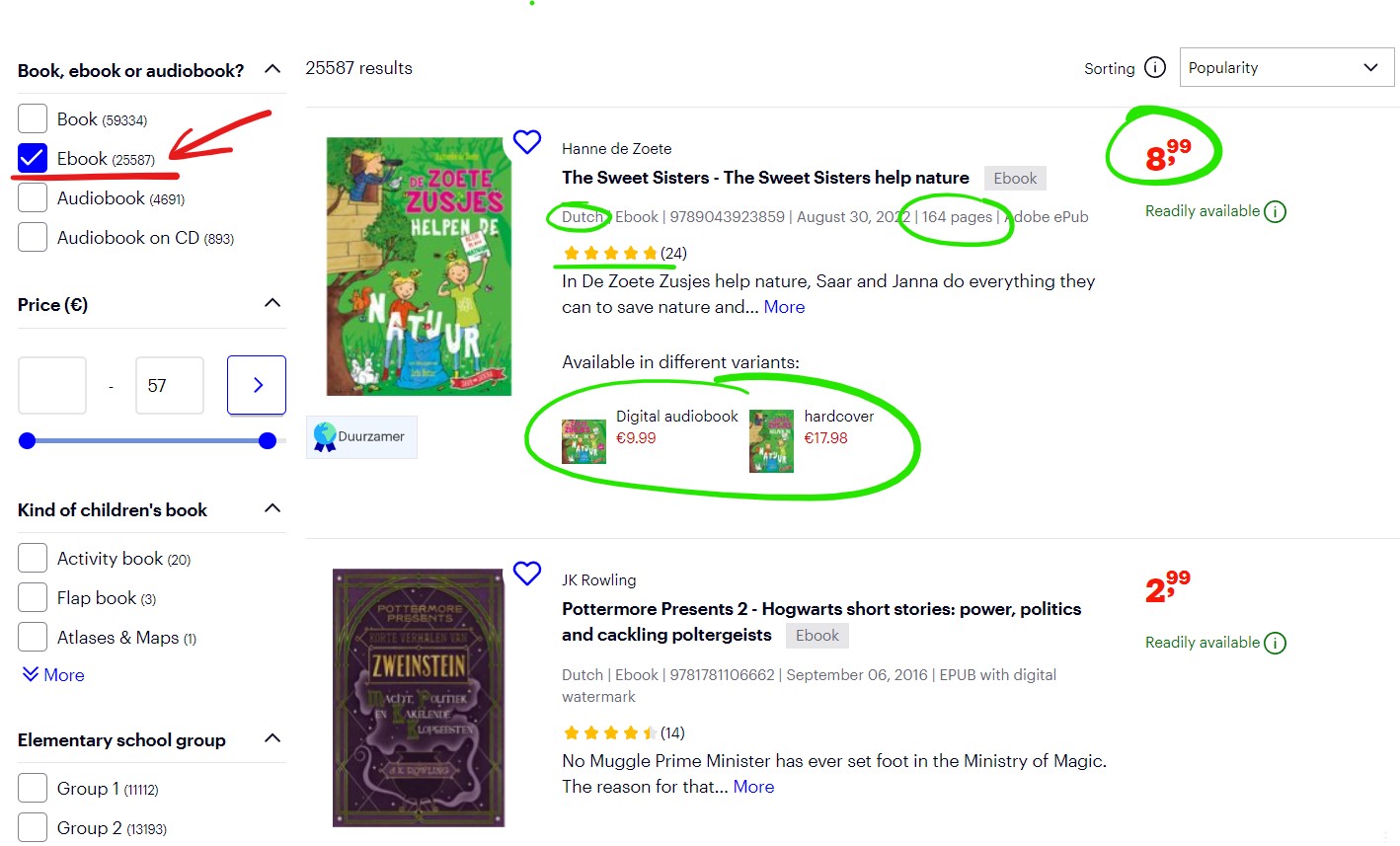 - Price
- Price 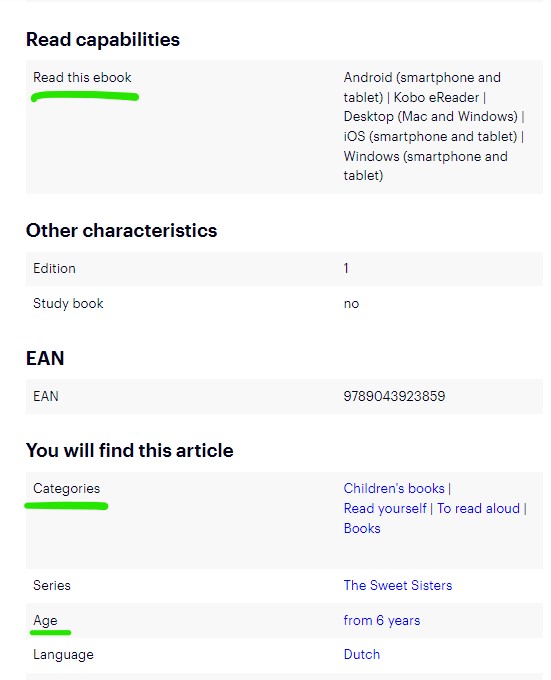


 proficient
proficient  native
native intermediate
intermediate  basic
basic  conversational
conversational